11.2.2021
Jakmile máme dostatečný počet vstupních dat (obrázků roztříděných příslušných kategorií), můžeme se pustit do prvních pokusů s trénováním neuronové sítě.
Pro neuronové sítě existuje několik použitelných frameworků. Vůbec nemá smysl je zkoušet všechny, vstupní bariéra je příliš vysoká. Já jsem začal s knihovnou fann na jednoduchých (deep) feed forward sítích (aplikace je stále užitečná: Artificial Intelligence Photovoltaic Analyser) a teprve později se přesunul k Tensorflow, konkrétně k verzi 1. Knihovně fann bych se dnes zdaleka vyhnul (kromě velmi specifických případů — knihovnu fann lze snadno spustit v mnoha instancích najednou). Tensorflow 1 už se dá využít k mnoha dalším úkolům, včetně zpracování videa. Použití Tensorflow 1 ale může vyžadovat znalosti matematiky, která je za neuronovými sítěmi schovaná. To nikdy není na škodu, otevírá to nové obzory pro využití neuronových sítí. Navíc ta matematika schovaná v neuronových sítích není složitá. Ale pro jednoduchou klasifikaci jednotlivých snímků videa není tak detailní znalost matematiky důležitá.
Tensorflow 2 funguje v trochu jiném režimu oproti Tensorflow 1 a návrh neuronové sítě není tak náročný na znalosti matematiky. Veškerá práce s neuronovými sítěmi se tak výrazně zjednodušuje.
Neuronové sítě umějí spoustu užitečných věcí. Jednou z těchto věcí je logistická regrese neboli klasifikace. O co jde? Podívejte se na obrázky, kterými hodláme Pásovce naučit, aby se vyhýbal překážkám v cestě. Obrázky jsou hezky rozdělené do čtyř kategorií (tříd, anglicky classes):
Záměrně jsem uvedl vedle sebe několik různých výrazů pro jednu věc: logistická regrese, kategorie, class, klasifikace, kategorizace. To je to, co od natrénované sítě chceme. Když neuronové síti předložíme k posouzení neznámý snímek, chceme, aby síť zařadila obrázek do jedné ze čtyř kategorií. Podle kategorie scény, kterou Pásovec právě vidí a vyhodnocuje, se pak provede příslušná akce.
Snímky z kamery zpracovává neuronová síť snímek za snímkem. Každý snímek je nezávislý na ostatních snímcích (na zpracování sekvencí obrázků bychom potřebovali rekurentní neuronovou síť — RNN, LSTM, GRU). Pro zpracování obrázků se s mimořádným úspěchem používají konvoluční neuronové sítě:
Konvoluční sítě doplňují neuronovou síť o další (konvoluční) vrstvy a výrazným způsobem snižují velikost celé sítě. Než se obrázek dostane do vlastní neuronové sítě, prochází množstvím konvolučních vrstev, které obrázek upravují tak, aby následná neuronová síť nemusela být příliš velká a aby bylo v jejích silách obrázek zpracovat.
Od naší neuronové sítě pro Pásovce chceme, aby rozeznávala čtyři různé kategorie snímků. Proto nám na výstupní vrstvě stačí pouhé čtyři neurony. Výstupem každého neuronu je jednoduchá informace: 1 = je to tato kategorie, 0 = není to tato kategorie. Neuronové sítě ale nefungují takto striktně. Ve skutečnosti neuronová síť kategorii pouze odhaduje, výstupem je proto hodnota někde mezi 0 a 1, která odpovídá pravděpodobnosti, s jakou jde o tuto konkrétní kategorii. Číslo 0 pak znamená "pravděpodobnost 0%", číslo 0,9 znamená "pravděpodobnost 90%". Tomu nejlépe odpovídá výstup z logistické funkce (sigmoida).
Zádrhel může nastat, když z neuronové sítě vylezou pravděpodobnosti:
Pokud nám některý snímek takto spadne do několika kategorií, dochází ke zmatení. Potřebujeme zajistit, aby nám ze sítě vypadla jediná kategorie a všechny ostatní byly potlačené. Místo sigmoidy potřebujeme použít funkci softmax. Tato funkce přepočítá všechny čtyři výstupy tak, aby součet pravděpodobostí byl roven jedné (100%). Pak už je rozhodování mnohem snazší:
Z tohoto výsledku je rozhodování jednoznačné: žádná z kategorií nemá ani 50% pravděpodobnost, takovému výsledku proto nemusíme věnovat žádnou pozornost. Neuronová síť na obrázku ve skutečnosti nedokázala poznat vůbec nic.
Ne poslední vrstvě je funkce softmax to, co chceme.
Pro spoustu úkolů z oblasti zpracování obrázků nabízí Tensorflow hotové řešení: Tensorflow Object Detection API včetně dobře zpracovaného tutoriálu. Neuronové sítě v Object Detection API jsou ale zbytečně předimenzované (dataset COCO má zhruba 100 kategorií!) a natrénované na datech, která nás vůbec nezajímají. Object Detection API se však dá využít jako výborný zdroj inspirace.
Neuronové sítě jsou velmi náročné na výkon při trénování, zpracování videa v Pásovci pak vyžaduje co nejrychlejší vyhodnocení každého snímku. Od neuronové sítě proto chceme, aby byla co nejjednodušší. Na vstup proto pošleme co nejmenší obrázek, na výstupu ponecháme jen čtyři neurony (pro každou kategorii jeden) a budeme se snažit, aby celá síť obsahovala co nejnižší počet trénovatelných parametrů.
Inspirovat jsem se nechal sítí VGG16. Nějaké odkazy:
Síť VGG16 je velmi jednoduchá a přímočará a není složité ji implementovat v Tensorflow a modifikovat ji pro vlastní, specifické účely. I když pro zpracování obrazu mohou existovat i vhodnější architektury (třeba GoogLeNet), je nutné pamatovat i na to, že neuronovou síť později musíme přenést do počítače v Pásovci. U složitější sítě to může dělat potíže.
Při modifikaci sítě musíme upravit vstupní tensor na rozměry uložených obrázků (640×160×3 — trojka je počet barevných kanálů) a výstupní tensor na počet hledaných kategorií (4).
Obrázky z obou kamer 320×160 jsou spojené do jednoho 640×160. Ideální by bylo zpracovávat obrázky v konvolučních vrstvách odděleně a až nakonec je spojit pro zpracování v neuronových vrstvách. To se dá v Tensorflow 2 vyrobit poměrně snadno. Inspirovat jsem se nechal tímto článkem:
Celá síť pak může vypadat třeba takto (obrázky vygenerované programem Tensorboard):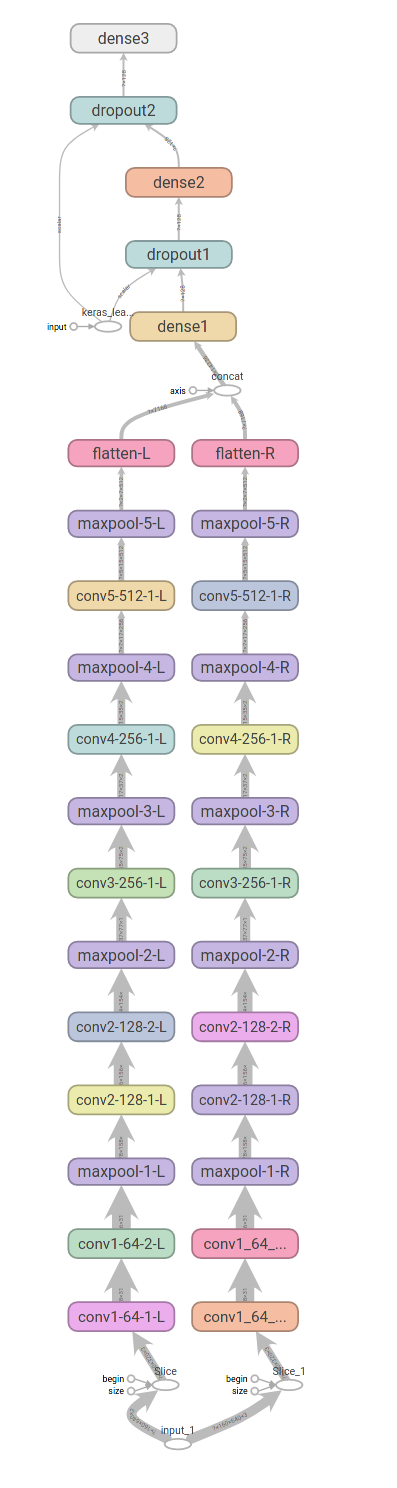
Kód sítě:
input = tf.keras.layers.Input(shape=(160,640,3)) inputL, inputR = tf.split(input, 2, axis=2) conv1_64_1L = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-1-L" )(inputL) conv1_64_2L = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-2-L" )(conv1_64_1L) maxpool1L = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-1-L" )(conv1_64_2L) conv2_128_1L = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-1-L" )(maxpool1L) conv2_128_2L = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-2-L" )(conv2_128_1L) maxpool2L = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-2-L" )(conv2_128_2L) conv3_256L = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv3-256-1-L" )(maxpool2L) maxpool3L = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-3-L" )(conv3_256L) conv4_256L = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv4-256-1-L" )(maxpool3L) maxpool4L = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-4-L" )(conv4_256L) conv5_512L = tf.keras.layers.Conv2D(512, activation='relu', kernel_size=(3,3), name="conv5-512-1-L" )(maxpool4L) maxpool5L = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-5-L" )(conv5_512L) flattenL = tf.keras.layers.Flatten( name="flatten-L" )(maxpool5L) conv1_64_1R = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1_64_1-R" )(inputR) conv1_64_2R = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1_64_2-R" )(conv1_64_1R) maxpool1R = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-1-R" )(conv1_64_2R) conv2_128_1R = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-1-R" )(maxpool1R) conv2_128_2R = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-2-R" )(conv2_128_1R) maxpool2R = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-2-R" )(conv2_128_2R) conv3_256R = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv3-256-1-R" )(maxpool2R) maxpool3R = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-3-R" )(conv3_256R) conv4_256R = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv4-256-1-R" )(maxpool3R) maxpool4R = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-4-R" )(conv4_256R) conv5_512R = tf.keras.layers.Conv2D(512, activation='relu', kernel_size=(3,3), name="conv5-512-1-R" )(maxpool4R) maxpool5R = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-5-R" )(conv5_512R) flattenR = tf.keras.layers.Flatten( name="flatten-R" )(maxpool5R) concat = tf.concat([flattenL, flattenR], axis = -1) dense1 = tf.keras.layers.Dense(128, activation='relu', name="dense1" )(concat) dropout1 = tf.keras.layers.Dropout(0.5, name="dropout1" )(dense1) dense2 = tf.keras.layers.Dense(128, activation='relu', name="dense2" )(dropout1) dropout2 = tf.keras.layers.Dropout(0.5, name="dropout2" )(dense2) output = tf.keras.layers.Dense(4, activation='softmax', name="output" )(dropout2)
Zásadní potíž pak nastala při převodu natrénované sítě na TensorRT engine pro Nvidia Jetson Nano. TensorRT nezná funkci split a nezabral ani slice. Nezbylo, než pravý a levý kanál zpracovávat společně:
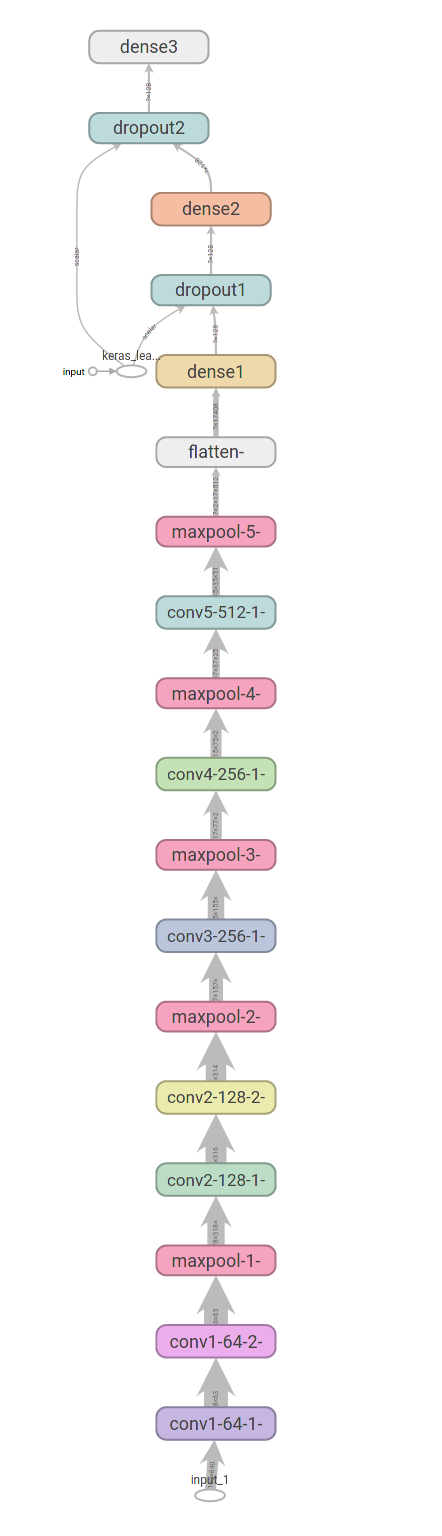
Kód sítě:
input = tf.keras.layers.Input(shape=(160,640,3)) conv1_64_1 = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-1-" )(input) conv1_64_2 = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-2-" )(conv1_64_1) maxpool1 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-1-" )(conv1_64_2) conv2_128_1 = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-1-" )(maxpool1) conv2_128_2 = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-2-" )(conv2_128_1) maxpool2 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-2-" )(conv2_128_2) conv3_256 = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv3-256-1-" )(maxpool2) maxpool3 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-3-" )(conv3_256) conv4_256 = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv4-256-1-" )(maxpool3) maxpool4 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-4-" )(conv4_256) conv5_512 = tf.keras.layers.Conv2D(512, activation='relu', kernel_size=(3,3), name="conv5-512-1-" )(maxpool4) maxpool5 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-5-" )(conv5_512) flatten = tf.keras.layers.Flatten( name="flatten-" )(maxpool5) dense1 = tf.keras.layers.Dense(128, activation='relu', name="dense1" )(flatten) dropout1 = tf.keras.layers.Dropout(0.5, name="dropout1" )(dense1) dense2 = tf.keras.layers.Dense(128, activation='relu', name="dense2" )(dropout1) dropout2 = tf.keras.layers.Dropout(0.5, name="dropout2" )(dense2) output = tf.keras.layers.Dense(4, activation='softmax', name="output" )(dropout2)
Propojení obou kanálů způsobuje prolnutí obou obrázků, levého a pravého, v místě jejich spojení. To je dáno vlastnostmi konvoluce. Do neuronové sítě (vrstvy dense1, dense2) se dostanou oba kanály mírně překryté. Dle mého názoru to může způsobovat horší rozlišení na okrajích zorného pole, ale tento názor nemám nijak podložený.
Z praktických výsledků vyplývá, že rozdělené zpracování obou obrázků dává nepatrně lepší výsledky (zde recall, vysvětleno dále) a trénování rozdělené sítě je mnohem rychlejší (druhý obrázek s časem na ose x). Obrázky jsem přiložil dva, na prvním je na vodorovné ose epocha (trénovací krok) a na druhém obrázku je na vodorovné ose čas (trénování rozdělené sítě trvalo 7 hodin, u nerozdělené sítě to bylo 16 hodin). Obrázky z Tensorboard:
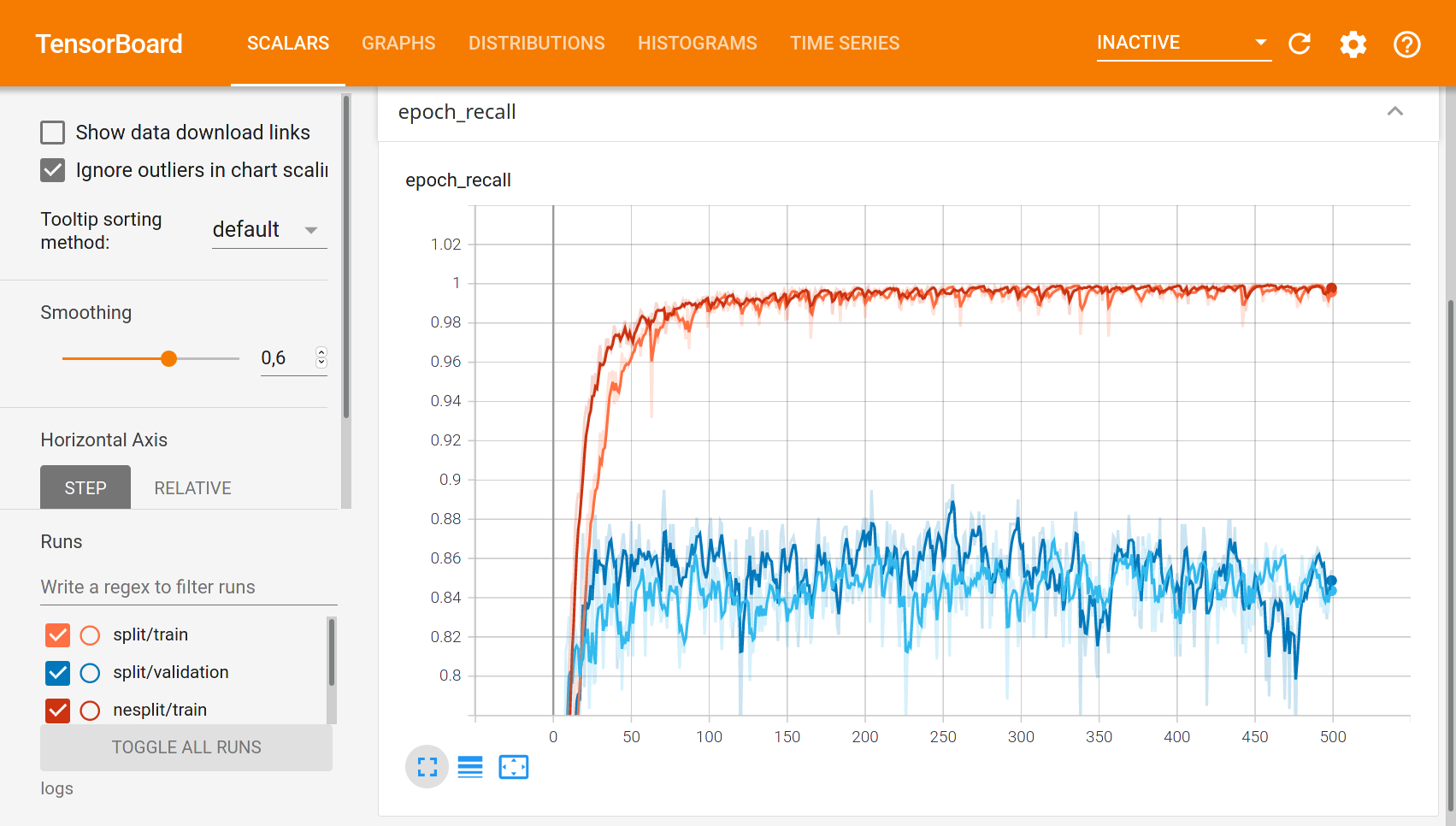
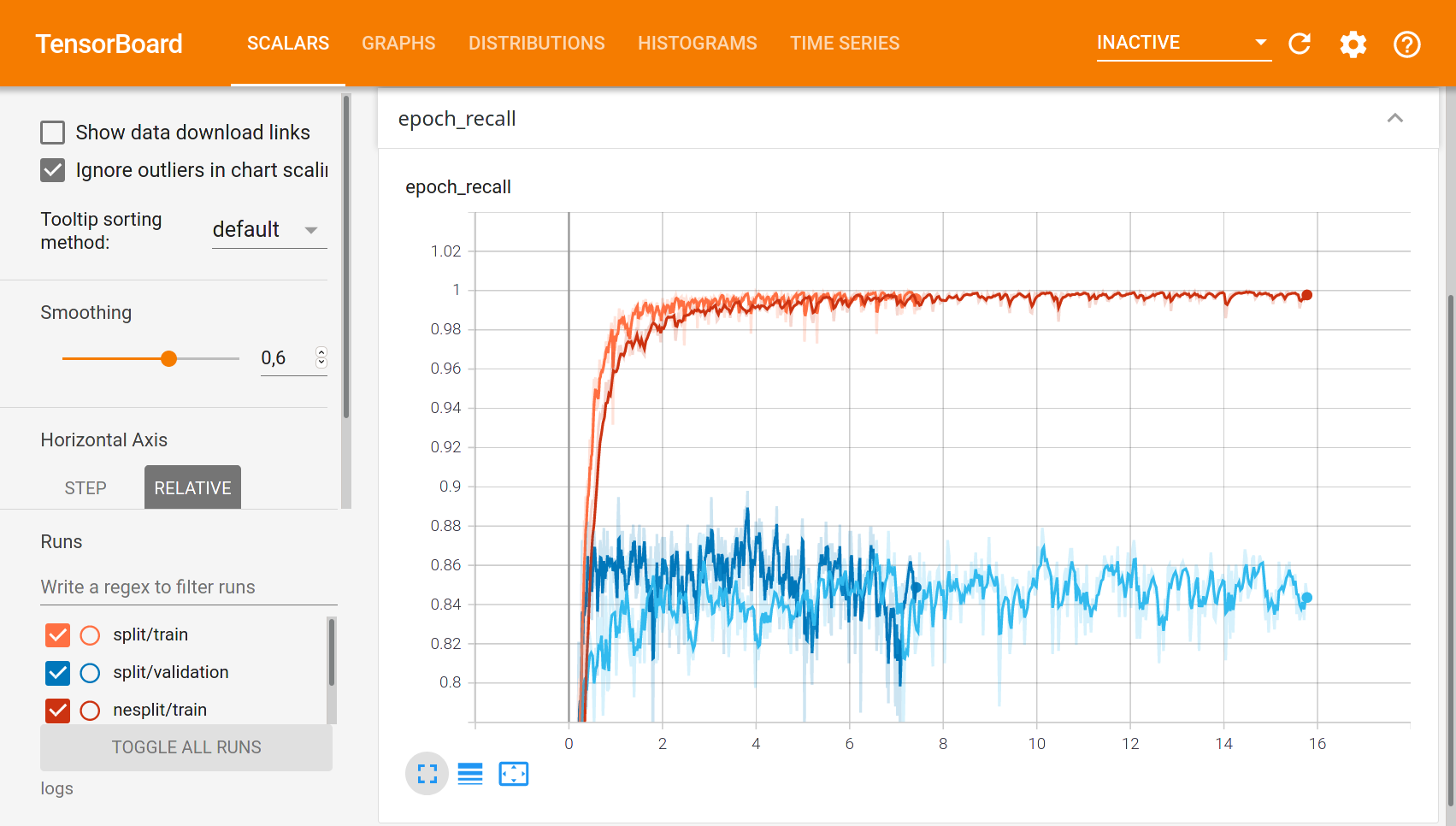
V grafu je zobrazená funkce recall pro trénovací množinu (červená) a pro kontrolní množinu (modrá) pro dvě různé sítě (rozlišeno odstínem). Trénovací množina nás úplně nezajímá, až vypustíme Pásovce do térenu, nebudeme zvědaví na to, co se Pásovec naučil zpaměti, ale na to, jak to dokáže aplikovat na neznámá data. Kontrolní množina, to jsou právě ona neznámá data, na kterých se neuronová síť neučila, a která slouží k otestování, jak se bude síť chovat v praxi.
Funkce recall je přesnou obdobou sensitivity u anti-covid testů. Hodnota funkce recall nám může prozradit, co se stane, když postavíme Pásovce před zeď. Vidíme, že zhruba v 85% se otočí a pojede jinudy, ale v 15% případů se pokusí projet skrz.
Dvojice kamer spojená do stereoskopického systému by mohla odhadovat vzdálenosti i jinak, přímo. Existuje pro to rozšíření do OpenCV, na internetu existují krásné články:
Mně se nikdy nepodařilo dosáhnout tak hezkých výsledků, prohlásil jsem to celé za slepou cestu pro Pásovce.
Ono nakonec snad ani není nutné depth mapu vyrábět. V každé dvojici obrázků ta informace je a neuronová síť by s ní měla umět pracovat, pokud by taková informace byla pro neuronovou síť užitečná. Nakonec i neuronové sítě jsou schopné z dvojice obrázků vytvořit depth mapu:
Nevím tedy, jestli takto postavená síť vnímá své okolí skutečně stereoskopicky, a jestli ano, nevěděl bych, jak to dělá. Snad to nevadí. Já vidím prostorově zcela určitě a taky nemám ani zbla ponětí o tom, jak to dělám.
Kompletní skript pro trénování neuronové sítě:
import tensorflow as tf
datagen = tf.keras.preprocessing.image.ImageDataGenerator(rotation_range=2, brightness_range=(0.5, 1.5), validation_split = 0.1)
train_generator = datagen.flow_from_directory(
"images", # Cesta k trénovacím obrázkům
classes=['OK', 'XX', 'XL', 'XR'], # Označení tříd, které trénujeme
target_size=(160,640), # Velikost obrázků
batch_size=32,
class_mode='categorical',
subset="training"
)
test_generator = datagen.flow_from_directory(
"images",
classes=['OK', 'XX', 'XL', 'XR'],
target_size=(160,640),
batch_size=32,
class_mode='categorical',
subset="validation"
)
# Vlastní DNN
# Konvoluční část
input = tf.keras.layers.Input(shape=(160,640,3))
conv1_64_1 = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-1" )(input)
conv1_64_2 = tf.keras.layers.Conv2D(64, activation='relu', kernel_size=(3,3), name="conv1-64-2" )(conv1_64_1)
maxpool1 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-1" )(conv1_64_2)
conv2_128_1 = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-1" )(maxpool1)
conv2_128_2 = tf.keras.layers.Conv2D(128, activation='relu', kernel_size=(3,3), name="conv2-128-2" )(conv2_128_1)
maxpool2 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-2" )(conv2_128_2)
conv3_256 = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv3-256-1" )(maxpool2)
maxpool3 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-3" )(conv3_256)
conv4_256 = tf.keras.layers.Conv2D(256, activation='relu', kernel_size=(3,3), name="conv4-256-1" )(maxpool3)
maxpool4 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-4" )(conv4_256)
conv5_512 = tf.keras.layers.Conv2D(512, activation='relu', kernel_size=(3,3), name="conv5-512-1" )(maxpool4)
maxpool5 = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name="maxpool-5" )(conv5_512)
flatten = tf.keras.layers.Flatten( name="flatten" )(maxpool5)
# Neuronová část
dense1 = tf.keras.layers.Dense(128, activation='relu', name="dense1" )(flatten)
dropout1 = tf.keras.layers.Dropout(0.5, name="dropout1" )(dense1)
dense2 = tf.keras.layers.Dense(128, activation='relu', name="dense2" )(dropout1)
dropout2 = tf.keras.layers.Dropout(0.5, name="dropout2" )(dense2)
output = tf.keras.layers.Dense(4, activation='softmax', name="output" )(dropout2)
callbacks = [tf.keras.callbacks.TensorBoard('/logs', histogram_freq=1, write_images=False)]
metrics = [tf.keras.metrics.CategoricalAccuracy(), tf.keras.metrics.Recall()]
# Learning rate chce trochu zmenšit, jinak to dělá neplechy
optimizer = tf.keras.optimizers.Adam(lr=0.0004)
model = tf.keras.Model(inputs=input, outputs=output)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=metrics)
model.summary()
model.fit(train_generator, epochs=500, verbose=1, validation_data=test_generator, callbacks=callbacks)
model.save("model")
Vlastní program pro trénování není očividně nic složitého. Samotné trénování však zabere spoustu času, opravdu velmi pomůže co nejvýkonnější grafická karta, třeba V100. Ale když nemáte bagr, poslouží i lopata. Moje lopata přehazuje data kolem deseti hodin, na CPU by se potřebný čas hodně prodloužil.
Neuronovou síť bychom tímto měli mít natrénovanou. Nyní už zbývá jen nasadit síť do Pásovce a vypustit do terénu.
Celé to vypadá jako hračka a skutečně o nic jiného ani nejde. Ale techniky zde popsané mají i obrovský význam v praxi. Tak jako může neuronová síť rozeznávat překážku nalevo či napravo, může rozeznávat i špatný či dobrý výrobek a udělat tak spoustu kvalifikované, ale monotonní a únavné práce. Jeden příklad za všechny:

Kolik toho vyrábí panel na obrázku? Jakou máme poslat předpověď výkupci elektrické energie? Kolik toho vyrobí tento panel, když se do něj opře sluníčko? Nemusíte být odborníky na fotovoltaiku a výsledek budete znát ihned: nula, nula, nula. Z dostupných dat to člověk nevyčte, z obrázku ihned. Totéž lze naučit i neuronovou síť!
