10.12.2019
Článek vzniknul jako vedlejší produkt přednášky na akci Tkalci na webu ve Valašském Meziříčí. Na akci se chystáme vzít systém pro rozeznávání obličejů a vysvětlit jeho funkci. V současné době je umělá inteligence dosti skloňované téma. I když jde o obor související s počítači, práce s umělou inteligencí se od běžného způsobu programování liší. Umělá inteligence je ve skutečnosti matematický obor s velkým přesahem do programování. Práce vývojaře neuronových sítí se podobá spíše práci chovatele nebo vychovatele, i když prostoru pro běžnou programátorskou práci je i zde dost. Neuronové sítě potřebují obrovské množství dat, které je nutné připravit do podoby vhodné pro neuronovou síť.
Na konci článku byste měli být schopní pochopit principy, na kterých funguje rozeznávání obličejů, a jaké technologie jsou na pozadí.
Odkaz na hraní, pokud se vám bude zdát článek příliš nudný:
A Neural Network Playground
V odkazu výše najdete online učební pomůcku pro tento tutoriál:
Introduction to Machine Learning

Nejjednodušší výklad funkce neuronové sítě vede přes regresní analýzu. Regresní analýza je statistická metoda, která dovede z různě zašuměných bodů (měření) odhadnout přímku, která by nejlépe odpovídala naměřeným hodnotám. I při neúplných datech dokáže regresní přímka předpovědět, jaké hodnoty y lze očekávat při různých vstupních hodnotách x. I když regresní analýza i neuronové sítě pracují obecně s různými funkčními průběhy, které se mohou od přímky významně lišit, v dalším textu se budeme věnovat pouze přímkám.
Neuronové sítě se často používají i pro klasifikaci – logistickou regresi. Pokud předložíme umělé inteligenci obrázek, neuronová síť je schopná odhadnout pravděpodobnost, s jakou se jedná o kočku, nebo o psa. Při tomto typu úlohy je nutné připravit obrovské množství obrázků psů a koček (minimálně desítky tisíc) a neuronovou síť natrénovat pro rozeznávání těchto dat. Výstupem takové klasifikační sítě pro rozeznávání psů a koček jsou pak dva signály: "Na 13% je to pes" a "na 92% je to kočka" (součet pravděpodobností by měl být 1, zde uvedený odhad pes nebo kočka je tedy s pravděpodobností 100% špatně).
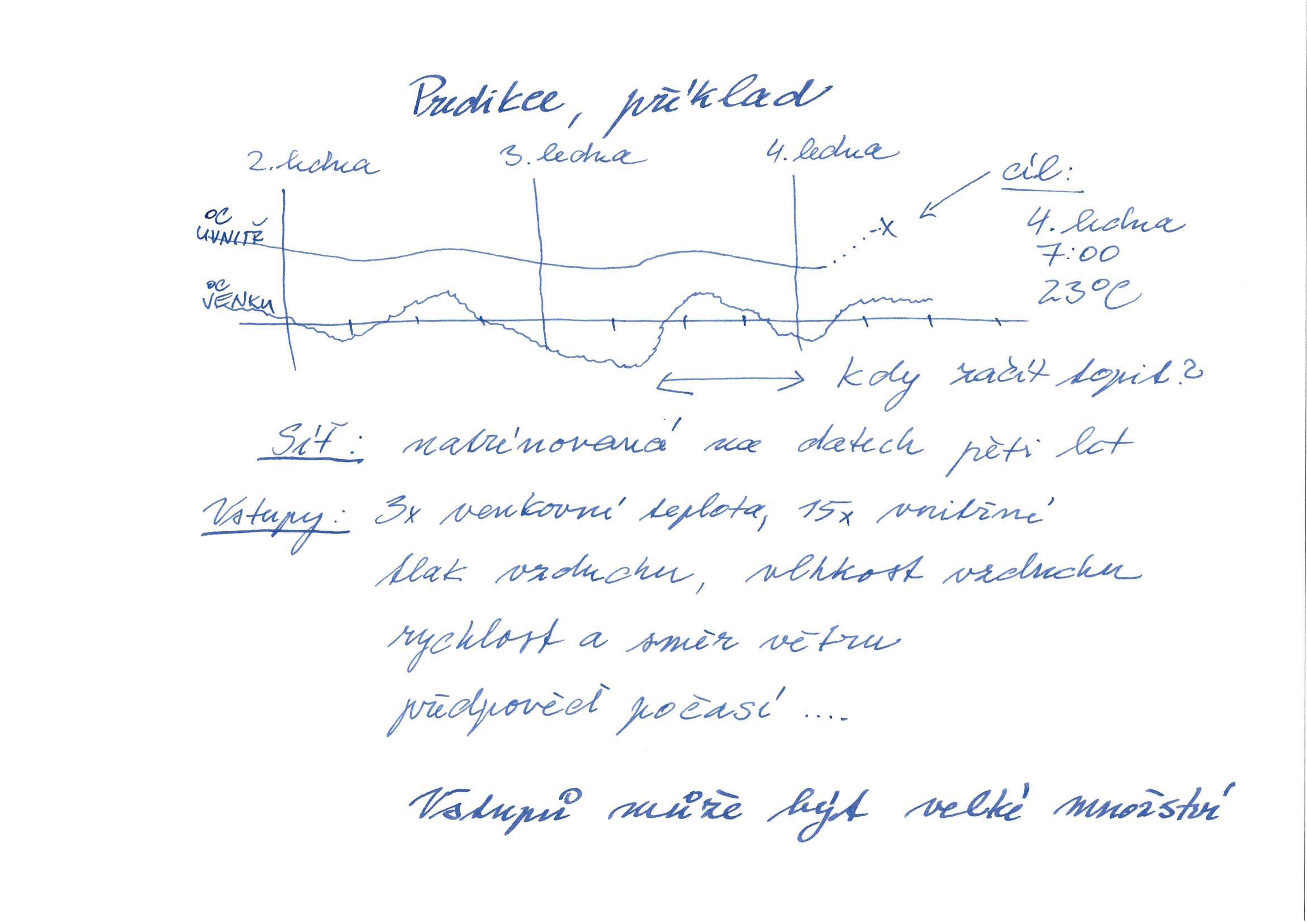
Neuronové sítě se často používají pro aplikace, kde se musí zpracovat velké množství vstupů, u kterých jen nejasně tušíme, jaký mají vliv na výsledek. Příkladem může být třeba ovládání vytápění v budově. Zde může neuronová síť dostat za úkol zapnout topení tak, aby při příchodu do práce v sedm ráno bylo v kanceláři příjemných 23 stupňů.
Vstupů, které taková síť může zpracovávat, může být nečekaně velké množství. Samozřejmě půjde o teplotu, ale teploměrů může být více jak venku, tak vevnitř budovy. Dalšími vstupy mohou být obecné údaje o počasí – tlak, vlhkost vzduchu, rychlost a směr větru či předpověď počasí. Mohou to být ale také údaje, které s počasím nesouvisí, ale na teplotu vliv mít mohou – například údaje ze zabezpečovacího zařízení (jsou okna zavřená?) nebo údaje z docházkového systému (kolik lidí je uvnitř budovy?)
Neuronová síť natrénovaná na základě údajů z předchozích let a případně i z mnoha jiných budov může tvořit velmi efektivní termoregulační systém budovy. Neuronová síť v tomto případě implementuje matematickou funkci, do které vstupují všechny výše uvedené údaje, a která počítá rychlost, s jakou se místnosti v budově ohřívají či ochlazují.
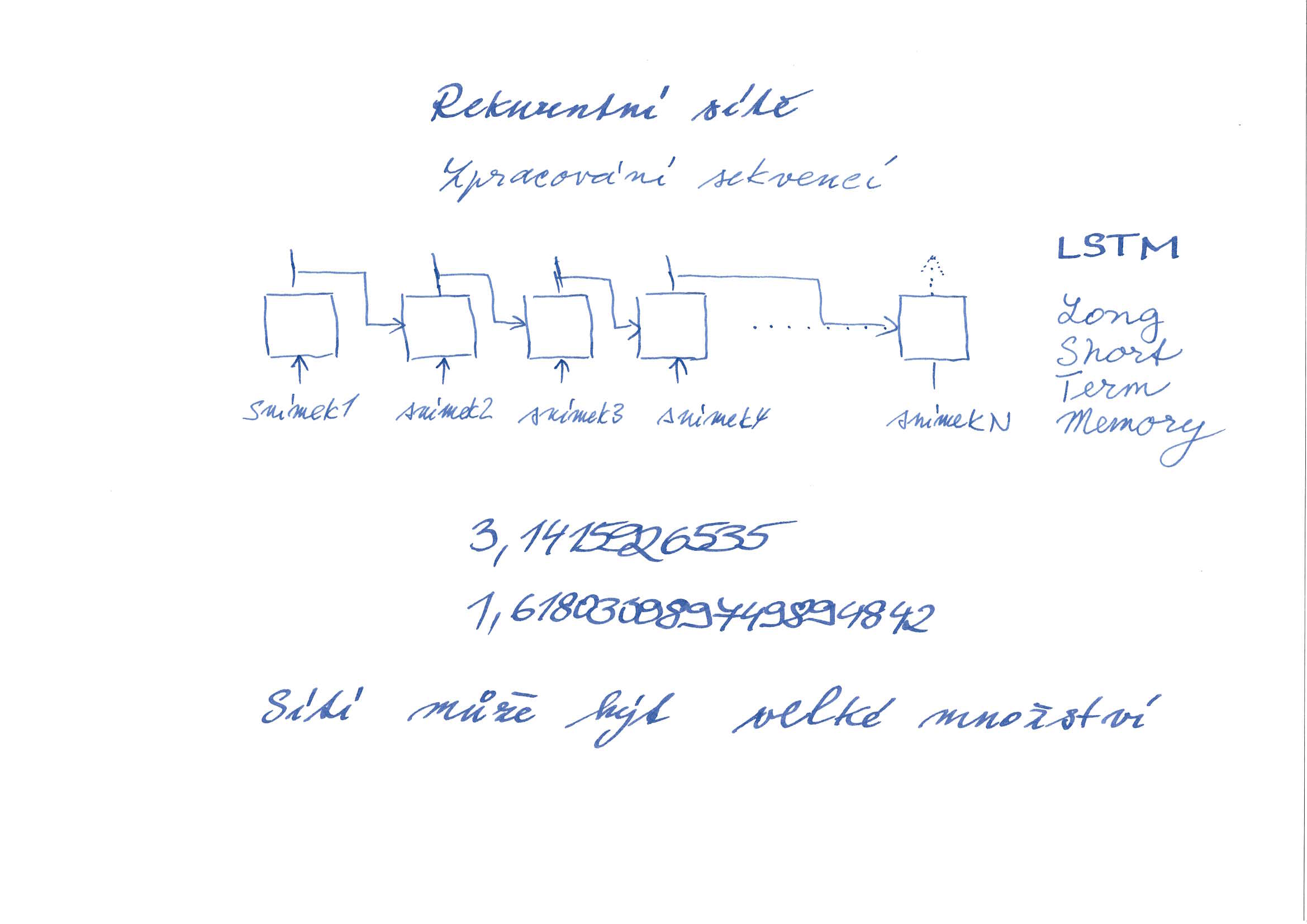
Stejně jako může do neuronové sítě vstupovat velké množství různých údajů, které spolu nemusejí na první pohled souviset, může systém umělé inteligence obsahovat i velké množství neuronových sítí. Typickým příkladem takového zapojení je rekurentní neuronová síť (RNN). Rekurentní sítě se používají pro zpracování dat, kde je důležité rozeznat kontext, v jakém se data pohybují.
Tento článek je o rozeznávání obličejů. Tuto technologii zaměstnáváme v kanceláři jako našeho inteligentního vrátného. Vrátný dokáže rozeznat, kdo se v kanceláři pohybuje, a podle toho vyvolat různé akce. Já mám například rád, když mi vrátný po mém příchodu do práce zapne počítač a uvaří kafe.
Aby byl vrátný schopný rozeznat, že jsem přišel, že nejsem na odchodu, musí mít více informací, než jen prostý údaj o tom, že se po kanceláři pohybuji zrovna já. Musí být schopný rozeznat sekvenci informací "otevřely se dveře – někdo vchází – rozeznávám šéfa" od sekvence "rozeznávám šéfa – otevřely se dveře – někdo odchází – zavřely se dveře".
Jsou to právě rekurentní neuronové sítě, které dokáží takový typ informace zpracovat. Rekurentní sítě se dnes používají například pro strojový překlad z jednoho jazyka do druhého, chatboty a podobně.
Jedním z použití RNN je například rozeznávání ručně psaného textu. Když se podíváte na obrázek, na zapsanou sekvenci číslic, zjistíte, že číslice se vzájemně překrývají. Nelze izolovat samostatnou číslici tak, aby do jejího zápisu nezasahovala jiná číslice. Rekurentní síť může číst text postupným načítáním úzkého sloupce pixelů. Kontext je při takovém zpracování textu důležitý. Nezpracovává se znak jediný, ale vždy se zpracovává několik znaků zároveň.
V souvislosti s rekuretními neuronovými sítěmi je užitečné si zapamatovat pojem "LSTM" – Long Short Term Memory. Jde o základní stavební buňku rekurentní neuronové sítě.
Výborný popis LSTM je k nalezení zde: Christopher Olah: Understanding LSTM Networks.
Často používanou alternativou k LSTM je GRU: Wikipedia: Gated Recurrent Unit
Pokud narazíte na generování šejkspírovských textů neuronovou sítí, půjde o inspiraci tímto článkem: Andrej Karpathy: The Unreasonable Effectiveness of Recurrent Neural Networks

Problematika neuronových sítí má velmi blízko ke statistice. Neuronové sítě se proto s úspěchem používají i pro statistické zpracování velkého množství dat.
Představte si například, že máte na disku uložený stoh fotografií lidí, a chtěli byste zjistit, kolik osob na fotografiích máte a roztřídit tyto fotografie na jednotlivé hromádky. To jako statistický úkol moc nevypadá.
Zkuste si ale představit jiný (v principu stejný) úkol: v datech z fotovoltaických elektráren najít stavy či chyby, které vedou ke snížení výkonu a k ekonomickým ztrátám. Předem nemusí být o chybách nic známo, neuronová síť přesto dokáže chyby najít a roztřídit do jednotlivých skupin podle charakteru chyby a spočítat pravděpodobnost jejich výskytu. Jde o stejný druh úkolu, jako v případě třídení fotek, zde ale o statistickém charakteru úlohy není pochyb.
Při rozhovoru s jedním regionálním ISP jsme přišli i na jiný zajímavý problém: ISP poskytuje připojení k internetu několika tisícovkám domácností. Provoz v jeho síti se neustále mění, ale v principu sleduje jisté zaběhané zvyklosti. Kolem dvou ráno bývá provoz nejmenší (ale stále poměrně vysoký), odpoledne a večer nejvyšší, v době štědrovečerní večeře prudce klesá... v provozu lze vysledovat množství pravidelností a vlivů, které mají na velikost provozu vliv. Do toho občas přijde nějaký útok nebo zavirovaný počítač. V provozu se vytvoří nepravidelnost, kterou by bylo možné pomocí neuronové sítě odhalit, a zastavit útok dříve, než dokáže napáchat významné škody.
Technika bývá označovaná jako učení bez učitele – unsupervised learning nebo clustering.
Data Clustering in C++: An Object-Oriented Approach (Chapman & Hall/Crc Data Mining and Knowledge Discovery)
Data Clustering: Algorithms and Applications (Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Book 31)
Peter Bruce, Andrew Bruce: Practical Statistics for Data Scientists

Mediálně nejvděčnější oblastí neuronových sítí je takzvaný "reinforcement learning", zde s velkou dávkou nadsázky označený jako "extrémní učení". S trochou štěstí dnes dokážeme naučít počítač hrát třeba Pacmana tak, že mu dáme k dispozici ovládání v podobě šipek na klávesnici a výstup z kamery namířené na displej počítače.
Záměrně jsem napsal "s trochou štěstí". Tento typ umělé inteligence má totiž obdivuhodný talent dělat úplně jiné věci, než bychom očekávali.
Pro tento typ umělé inteligence totiž potřebujeme vytvořit systém odměn a trestů, které dokážou neuronové síti říci, jestli postupuje správně nebo špatně. A právě v naší neschopnosti vytvořit takový systém může být schované čertovo kopýtko. Představte si, že máte robota s kamerou, kterého chceme naučit procházet bludištěm:
Umělá inteligence se velmi rychle naučí, že nejvyššího skóre dosáhne, když co nejrychleji vyjede z hracího pole. Jakýkoliv jiný postup povede k rychlému odečítání bodů a sto bodů za úspěšně absolvování cesty bludištěm bude tak nedosažitelný cíl, že se o něj umělá inteligence vůbec nebude pokoušet. Neuronová síť zde uvízne v lokálním minimu, ze kterého se bez změny systému odměn a trestů nikdy nedokáže vymanit.
Velmi zajímavý článek o současném stavu reinforcement learningu je k přečtení zde: Alex Irpan: Deep Reinforcement Learning Doesn't Work Yet

Nyní už asi tušíte, že neuronová síť je matematické udělátko, které dokaže napodobit podle trénovacích dat libovolný funkční průběh. Pokud zjednodušíme tento funkční průběh na jednoduchou přímku, neuronová síť nedělá nic jiného, než obyčejnou lineární regresi – podle známých, naměřených dat určí parametry přímky, která nejlépe vystihuje naměřená data.
Lineární regrese je jednoduchá a existují statistické postupy, jak parametry přímky určit. U složitějších funkcí ale takové postupy neznáme. Neuronová síť proto v režimu učení hledá parametry funkce ze začátku zcela náhodnými pokusy a postupně upřesňuje funkční průběh tak, aby odchylka (chyba) od trénovacích dat byla co nejmenší. Množství trénovacích dat i množství hledaných parametrů funkce může být ohromné. Hledání funkčního průběhu je proto velmi náročně na výpočetní výkon.
Inference – odvození – může být naproti tomu velice rychlé, takže pro využití natrénované neuronové sítě stačí i relativně slabý hardware. Proto může běžet třeba rozeznávání obličeje i v mobilním telefonu. Mobilní telefon je přitom z hlediska výkonu takový typický "počítač na baterky".

V oboru umělé inteligence a neuronových sítí se vyskytuje neobvyklé názvosloví, na které nemusí být běžný vývojář zvyklý. Některé základní pojmy proto proberu.
Data se ukládají v různých strukturách, které mají svá jména:
Pozor! Vektor nemá nic společného s postavičkou z Mimoňů, ani s vektorem, jak jej používáme ve fyzice. Jde prostě o řadu hodnot zabalených do jedné buňky (proměnné).
Matice je totéž co vektor, ale ve dvou rozměrech. Matice má výšku i šířku, zatímco vektor má rozměr jen jeden. Matice zde uvádím proto, že počítání s maticemi je známé, hojně využívané a řada vývojařů zná matice ze školy nebo ze zpracování grafiky.
Tensor je potom matice zobecněná na libovolný počet rozměrů. Do tensoru můžeme zabalit třeba obrázek: šířka × výška × počet barevných kanálů. Obyčejný, plochý obrázek tak ukládáme do třírozměrné datové struktury.
Používání tensorů má svůj význam. Struktura neuronové sítě se totiž velice snadno popisuje pomocí maticových operací, jak si ukážeme dále.
Tensory můžeme dosadit i do naší staré známé rovnice přímky. Přímku pak už ale nebudeme moci nakreslit na papíře. Naše představivost končí s třetím rozměrem, dál už jde o matematickou abstrakci. I přes mnohorozměrnost prostorů je však matematický zápis velmi jednoduchý a stále dobře čitelný.

Optimizer, loss funkci a metriku proberu za chvíli podrobněji. Na tomto místě vysvětlím pouze pojem "regularizace".
Neuronové sítě mají nepříjemnou vlastnost: pokud je neuronová síť naddimenzovaná, dokáže se síť nabiflovat trénovací data "zpaměti" a ztratí schopnost zobecnění. Bránit se lze různými způsoby. Například se omezí velikost sítě, nebo se proces učení zastaví s předstihem. Další možností je regularizace: síť se trénuje tak, aby váhy byly co nejnižší (L2), nebo byly nulové (L1). Často se používá i dropout – v průběhu trénování se náhodně vypíná část neuronů.
Když se učíme například na zkoušku, snažíme se ve skutečnosti minimalizovat rozdíl mezi tím, co je napsané v učebnici, a tím, co později řekneme u zkoušky. Ideální stav je, pokud se naučíme učebnici zpaměti. Potom je chyba – odchylka mezi textem v učebnici a mezi textem v naší hlavě – nulová. Stav je však ideální jen zdánlivě – naučit se celou učebnici zpaměti spotřebuje obrovské množství energie a času a nemá praktický význam. Navíc učení by nemělo smysl, pokud bychom nedokázali zobecňovat. Nesmí nás rozhodit, pokud se zkoušející zeptá na něco, co v učebnici přímo není, ale z látky v učebnici to vyplývá.
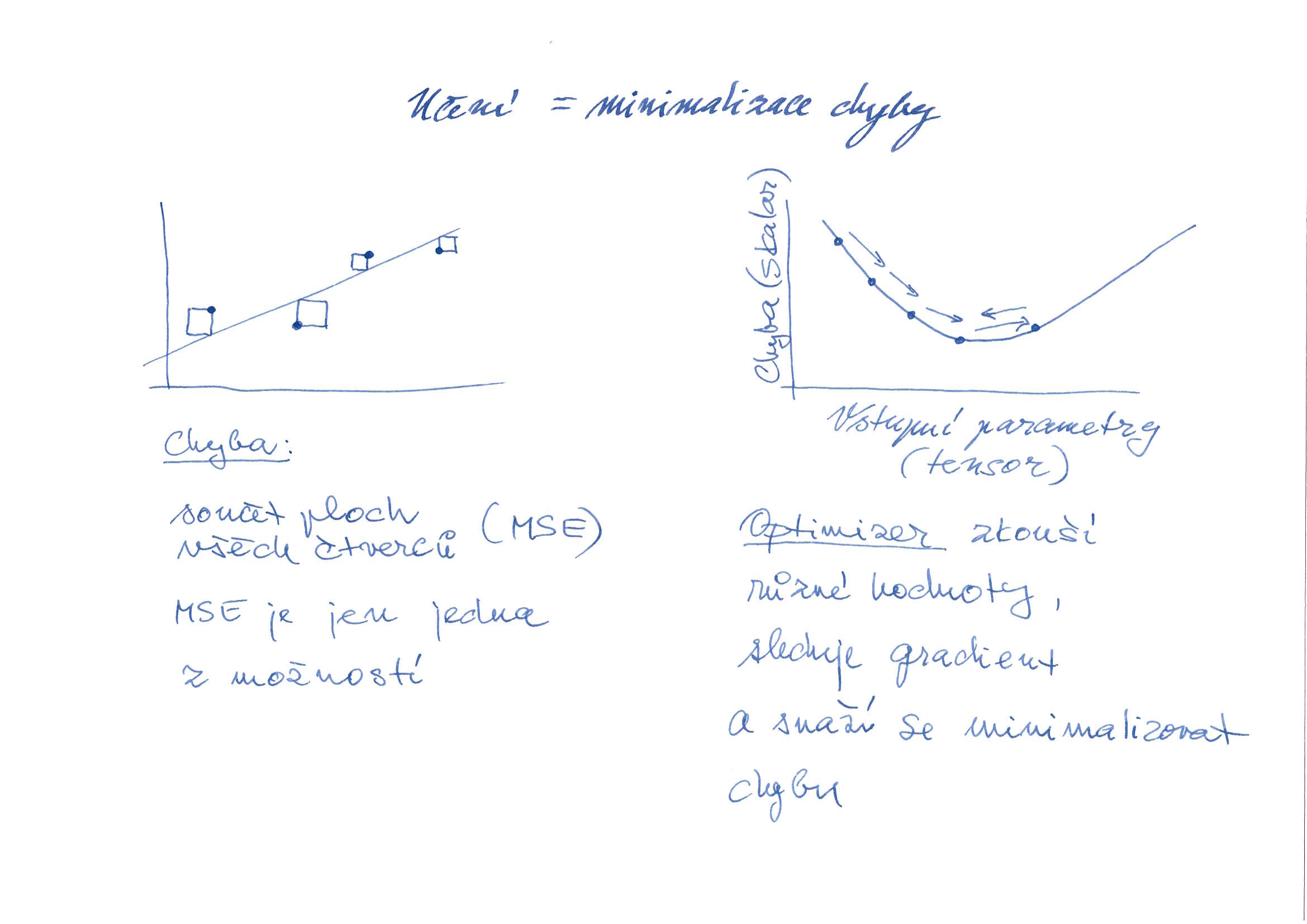
Loss function – způsob výpočtu chyby mezi hodnotou vypočtenou neuronovou sítí a mezi hodnotou očekávanou podle trénovacích dat. Velmi často se používá metoda nejmenších čtverců (MSE). Metoda nejmenších čtverců je ale jen jedna z možností, například u logistické regrese se používají spíše jiné způsoby pro výpočet chyby. Výsledkem chybové funkce je vždy jedna skalární hodnota.
Optimizer je algoritmus, který vyhledává optimální parametry neuronové sítě. Obecně se dá říci, že optimizer zkouší různé hodnoty a porovnává hodnotu chybové funkce při takto nastavených parametrech. Podle toho, jestli se chyba zmenšuje nebo zvětšuje, optimizer volí směr, kterým upraví parametry neuronové sítě. Různé algoritmy mohou volit různé strategie, které vedou k cíli různou rychlostí, nebo mají rozdílnou odolnost proti uváznutí v lokálním minimu.
I když máme neuronovou síť natrénovanou a chyba je malá, je potřeba nějak vyhodnotit její práci. Představte si, že trénujete síť pro prohledávání internetu (to je to, co dělá Google). Potom máte možnost vyhodnotit výsledky vyhledávání několika různými způsoby:
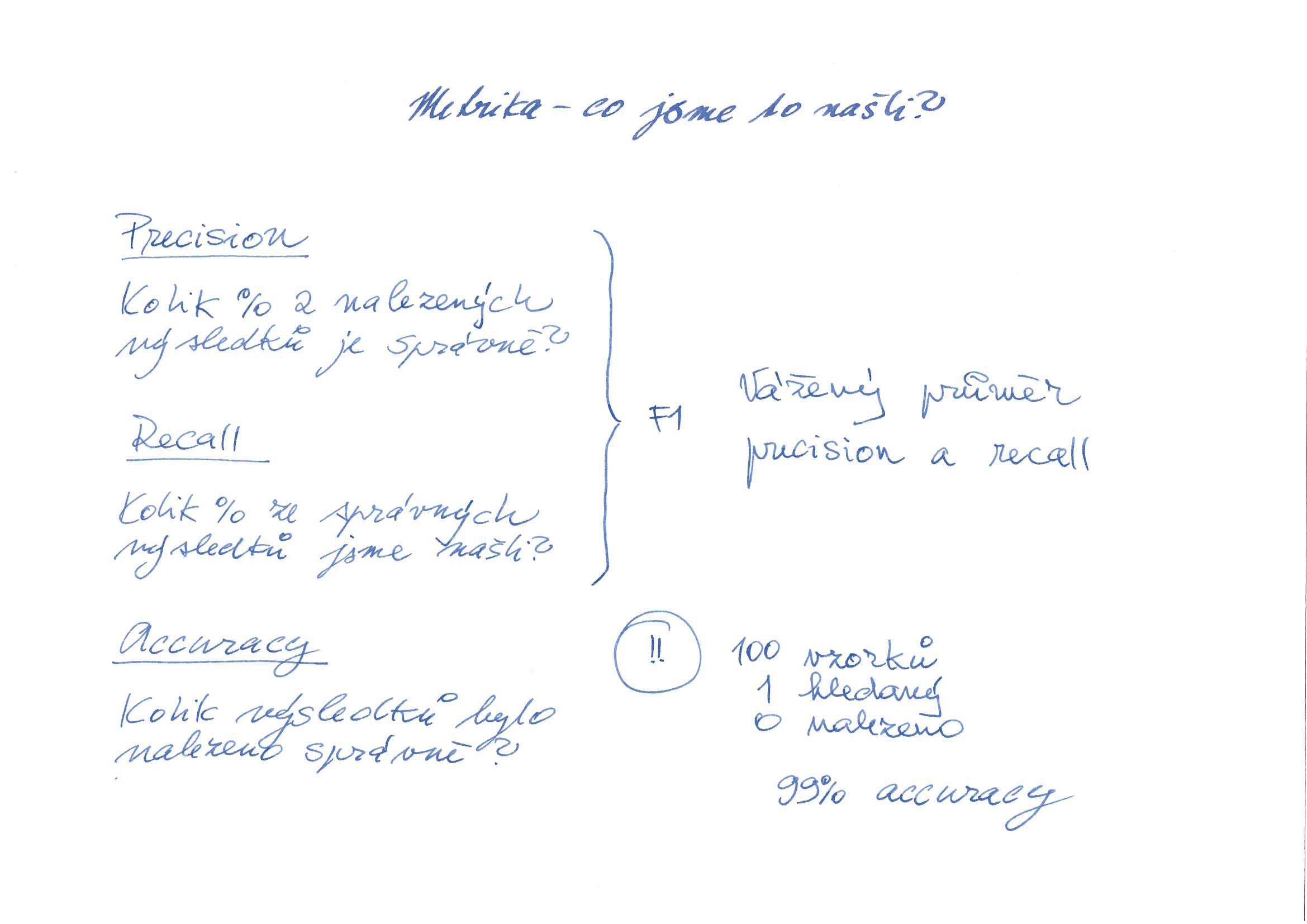
Recall: Kolik procent z nalezených výsledků je správně? Mělo být nalezeno 100 výsledků, ale nalezlo se jen 80. Je to málo? Je to hodně?
Precission: Kolik procent z nalezených výsledků se týká tématu? Nalezeno bylo 100 výsledků, ale jen 80 z nich se týká tématu. Zbytek jsou nesmysly. Vyhovuje to?
Accuracy: Jak je důležité vyhodnotit práci neuronové sítě tím správným způsobem, lze ilustrovat na další situaci: Máme sto prohledávaných stránek a jen jednu stránku, která se týká tématu. Vyhledávací algoritmus (neuronová síť) však označí všechny stránky za irelevantní. 99% stránek je označeno správně, ale výsledek je zcela k ničemu, protože jediný výsledek, který nás zajímal, je ztracený mezi jinými, správnými výsledky, které nás ale nezajímají.
Metod pro oznámkování sítě existuje nepřeberné množství, recall, precission a accuracy jsou zde uvedené jen pro jejich názornost.
Odkazy:
Precision and recall
Best loss function for F1-score metric
Streaming f1-score in Tensorflow: the multilabel setting

Jeden neuron implementuje v principu velmi jednoduchou matematickou funkci. Celým tímto textem se táhne rovnice přímky – lineární funkce. Svět kolem nás ale není lineární. Neuron je proto doplněný o nelinearitu v podobě aktivační funkce. Zde může velmi snadno dojít ke zmatení – běžný vývojář si pod aktivací představí něco jiného. Něco, co na začátku zpracování nastaví výchozí hodnoty. U neuronu však aktivace znamená něco jiného.
Dobře to lze vysvětlit na perceptronu. To je speciální případ neuronu – jeho výstupem je buď jednička, nebo nula. Představte si, že na vstupy perceptronu připojíte teploměr v různých částech místnosti. Každý teploměr dostane různou důležitost (váhu) a perceptron podle teploty bude zapínat (aktivovat) nebo vypínat topení. Odtud název "aktivační funkce".
U neuronu není aktivační funkce tak jednoduchá. Často se používají funkce typu sigmoida, hyperbolický tangens, relu nebo softmax. Aktivační funkce zde nepřepíná do stavu "aktivováno" či "dezaktivováno", ale určuje, jak moc je výstup neuronu "vybuzený" hodnotami na vstupu.
Odkazy:
Activation Functions in Neural Networks and Its Types
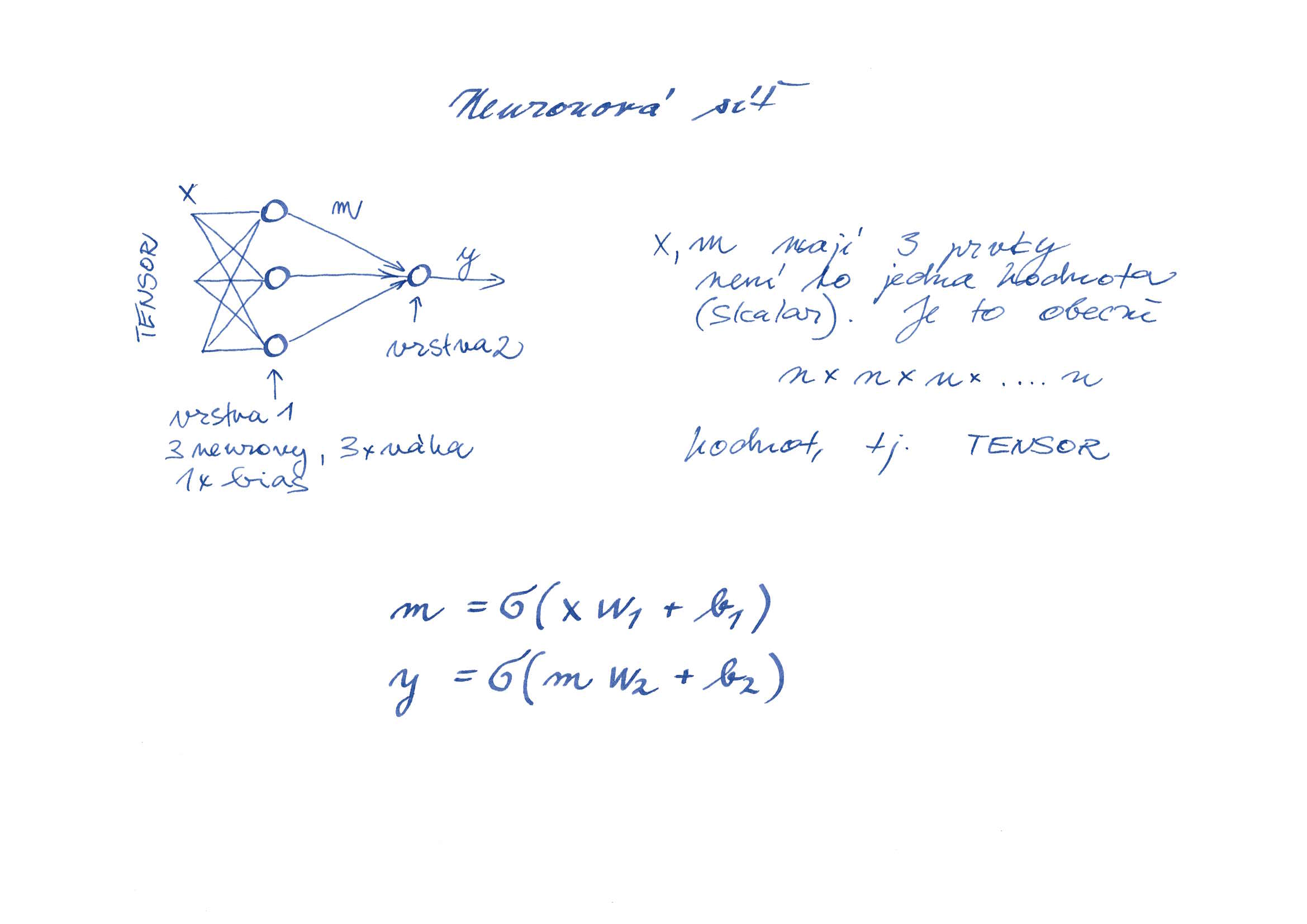
Když se zapojí několik neuronů dohromady, vznikne neuronová síť. Tak, jak jsme přidali k neuronu několik vstupů a matematický zápis zůstal stejný, zůstane stejný zápis i v případě, že přidáme několik neuronů. Zápis je podobný jako v případě přímky (až na zavedenou nelinearitu):
m = σ(xw₁ + b₁)
y = σ(mw₂ + b₂)
Každé písmenko zde zastupuje tensor:
x – vstupní hodnoty
w₁ – váhy jednotlivých vstupů první vrstvy, matice 3×3
b₁ – bias první vrsty
m – výstup první vrstvy, současně vstup první vrstvy
w₂ – váhy jednotlivých vstupů druhé vrstvy, matice 1×3
b₂ – bias druhé vrsty
σ – nelineární funkce
Tento matematický zápis zde neuvádím samoúčelně. Právě tímto způsobem se totiž zapisuje struktura neuronové sítě v TensorFlow:
w1 = tf.Variable(tf.random.truncated_normal([3, 3])) b1 = tf.Variable(tf.random.truncated_normal([3])) m = tf.matmul(x, w1) m = tf.add(m, b1) m = tf.nn.sigmoid(m) w2 = tf.Variable(tf.random.truncated_normal([1, 3])) b2 = tf.Variable(tf.random.truncated_normal([1])) y = tf.matmul(y, w1) y = tf.add(y, b1) y = tf.nn.sigmoid(y)
Pro tento okamžik opustíme popis neuronové sítě a přesuneme se více ke zpracování obrazu. Do neuronové sítě můžeme pustit obrázek pixel po pixelu, ale už obrázek s poměrně nízkým rozlišením 480x480 bodů obsahuje celkem 230 400 pixelů ve třech různých barevných kanálech (dohromady 691 200 bajtů). Pokud bychom chtěli takové množství informací zpracovat neuronovou sítí přímo, hned první vrstva by obsahovala 691 200 neuronů a 4,777×10¹¹ vah. To je ohromné, nepoužitelné množství. Proto se používají techniky, které vedou k redukci zpracovávaných dat – konvoluce.
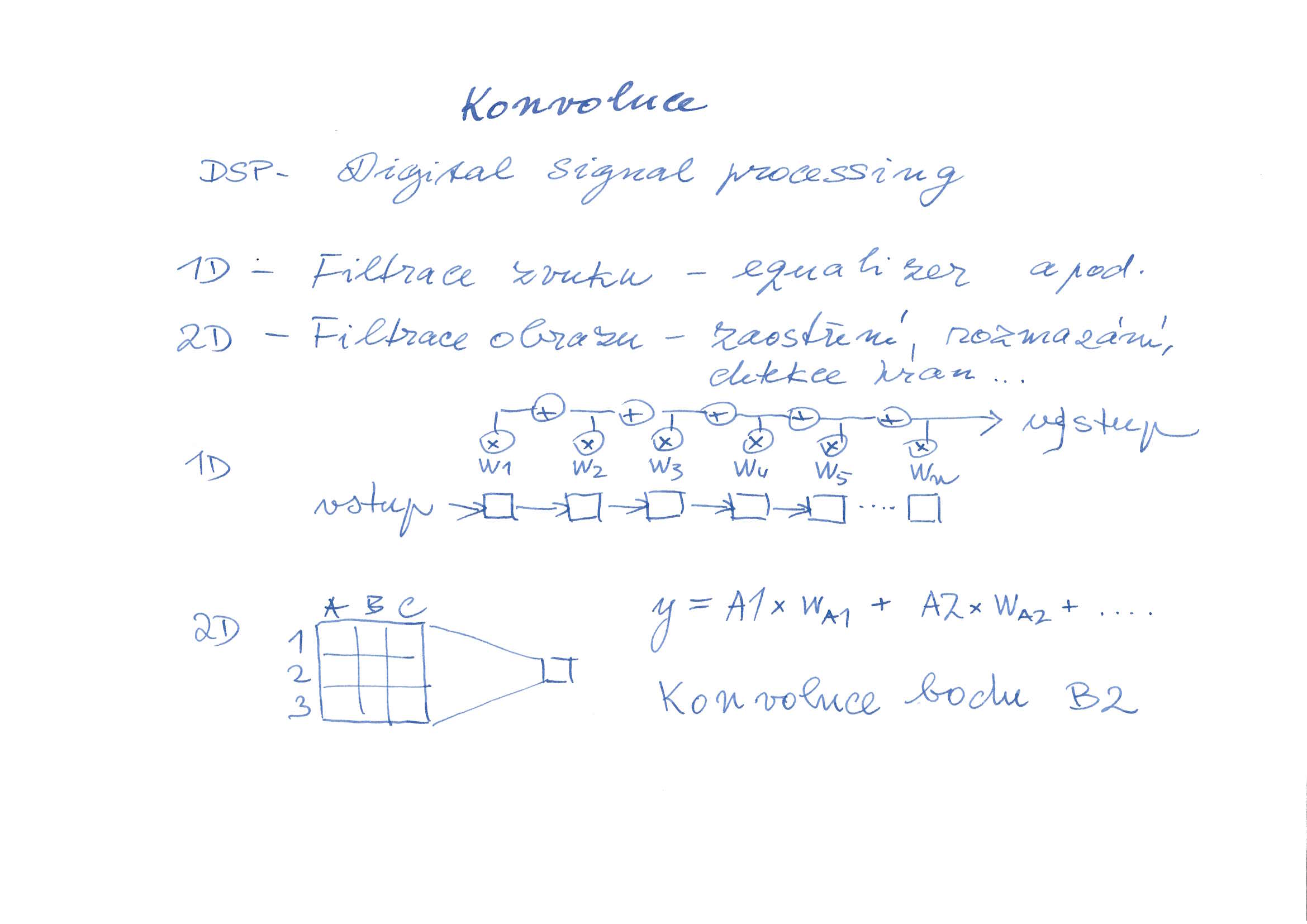
Konvoluce je jednoduchá matematická operace, která se už dlouho používá k digitálnímu zpracování signálů (DSP – digital signal processing). U zvuku se konvolucí řeší například ekvalizér, který dovede například zvýraznit nebo potlačit basy či výšky. U obrazu dokáže konvoluce například zaostřit nebo rozmazat obrázek, zvýraznit hrany a podobně. Velké množství filtrů v programech pro manipulaci s obrázky (například Gimp či Photoshop) je řešeno právě konvolucí.
Princip konvoluce je jednoduchý. Například konvoluce jednoho bodu u obrázku v sobě zahrnuje i několik bodů okolo, každý bod s jinou váhou. Právě váha každého bodu je to, co rozhoduje o funkci filtru – jedno nastavení vah dovede obrázek například zaostřit, jiné nastavení vah dokáže obrázek naopak rozmazat.
V praxi DSP se pro návrh filtrů používají Fourierovy transformace, blíže se lze dozvědět ve skvělé knize: The Scientist and Engineer's Guide to Digital Signal Processing.
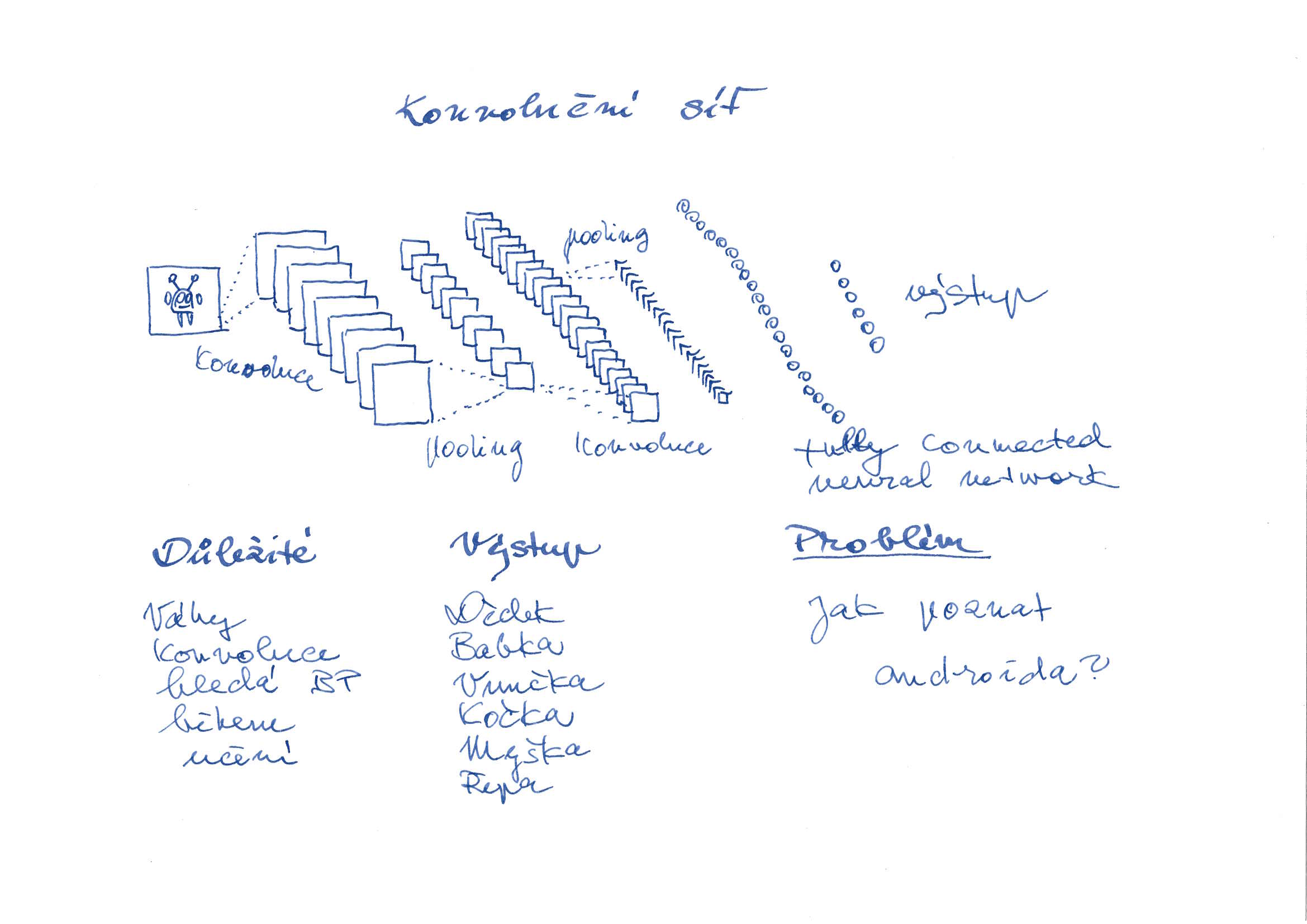
Pro zpracování obrázků se zakomponovala konvoluce přímo do neuronové sítě. První vrstvy konvoluční neuronové sítě (CNN) slouží k výběru (filtraci) různých charakteristik obrázku (feature maps) a k redukci množství pixelů (subsampling či pooling – obojí znamená totéž).
V konvoluční síti se vyskytují dva typy vrstev ve dvojicích za sebou:
Vrstev konvoluce – pooling může být několik za sebou. Tak se zvýší počet obrázků v mezivrstvách (označují se jako feature maps), ale podstatně se zmenší velikost obrázku.
Nakonec se přivedou data do normální neuronové sítě (fully connected vrstva).
Zde je důležité si uvědomit, že váhy v konvoluci se nastavují v průběhu učení (back-propagation). Konvoluční síť si tedy sama vytváří filtry, které pro svou činnost potřebuje.
Pokud je síť zapojená, jak je namalováno na obrázku, vzniká samozřejmě problém. Síť je trénovaná na rozeznávání postaviček z pohádky o veliké řepě a když jí ukážeme androida, nedokáže ho rozeznat.
Odkazy:
https://adventuresinmachinelearning.com/convolutional-neural-networks-tutorial-tensorflow/

Od konvoluce odskočím k dalšímu tématu. Embedding je technologie, která umí hledat souvislosti mezi různými prvky. V příkladech se často uvádí zpracování jazyka.
Na obrázku jsem namaloval abecedu. To je typický příklad náhodně uspořádané sekvence. Přitom některá písmenka jsou si mnohem blíže, než jiná. Zaměnitelné mohou být například samohlásky, proč tedy nejsou v abecedě vedle sebe? Podobná samohláskám jsou i písmena R a L, ve slovenštině se dokonce mohou psát dlouze, s čárkou: "Akú dĺžku má vrták, ktorým ktosi čosi vŕce v paneloch?". V češtině jde o písmena slabikotvorná: vlk, strk. Na druhou stranu se R a L používají především jako souhlásky, blíže mají k písmenům jako P, N, M a podobně. Zaměnitelná však nejsou.
Poskládat abecedu podle příbuznosti písmen se nám nepodaří, určitě ne v jednom rozměru. Může se nám to ale podařit, pokud si přibereme rozměrů více.
Jakmile se začneme pohybovat v n-rozměrném prostoru, začne se nám pracovat mnohem lépe. Každé písmeno má své souřadnice a díky tomu můžeme velmi snadno počítat vzdálenost (příbuznost) mezi různými písmeny. Ve 2D prostoru stačí pro výpočet vzdálenosti například Pythagorova věta, kterou lze snadno rozšířit i do obecného n-rozměrného Eukleidovského prostoru. Trochu komplikovanější je nalezení nejbližších sousedů, k tomu se používá algoritmus KNN (K-nearest neighbors).
V reálných úlohách nám tři rozměry nestačí, používá se mnohem vyšší počet rozměrů. Pro snazší představu a vizualizaci lze počet rozměrů zredukovat algoritmem t-SNE (t-distributed stochastic neighbor embedding).

Embedding pracuje na principu predikce. Představte si větu
Probudil jsem se, vedle mne ležela…
Embedding je schopný určit pro každé slovo pravděpodobnost, s jakou se toto slovo může ve větě vyskytnout. Slovo "manželka" bude mít pravděpodobnost velmi vysokou, slovo "lokomotiva" naopak velmi nízkou. To, že embedding označil pravděpodobnost lokomotivy jako nenulovou, bude způsobené pravděpodobně tím, že neuronová síť příliš často čučela na akční filmy.

Chceme-li vybudovat systém pro rozeznávání obličeje, jsme stavění hned před dvě úlohy:
V praxi je vše složitější a pro zvýšení pravděpodobností úspěšné identifikace se řeší úlohy hned čtyři:
Rozeznávání obličeje je výborně popsáno zde:
Machine
Learning is Fun! Part 4: Modern Face Recognition with Deep Learning.
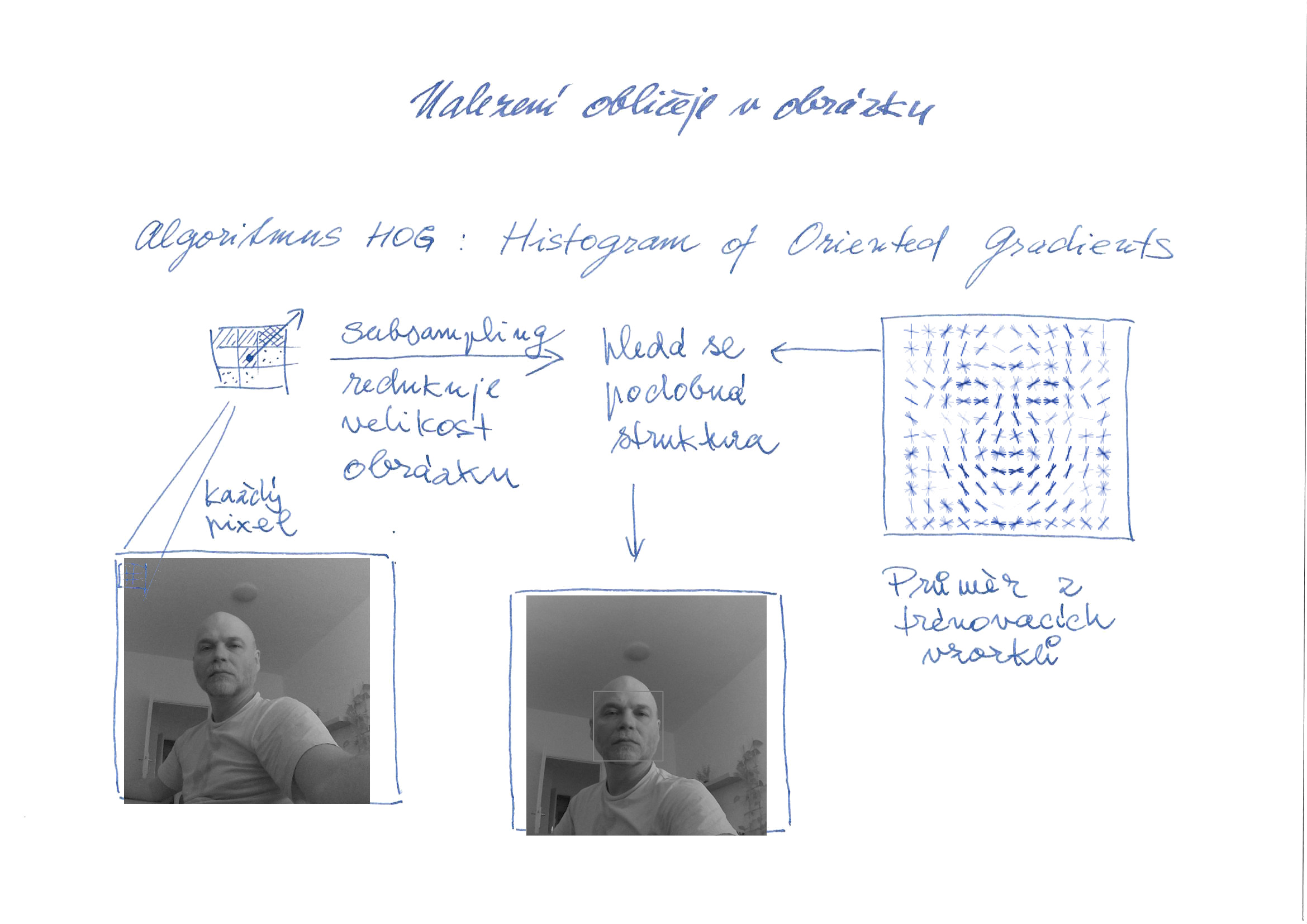
Velkým problémem při rozeznávání obličeje je různá úroveň osvětlení. Různě osvětlené mohou být nejen různé snímky, ale i různé části obličeje. Pokud na jednu polovinu obličeje svítí slunce, druhá polovina obličeje může být utopená ve tmě. Algoritmus HOG proto vytváří mapu gradientu jasu, kterou porovnává s průměrnou hodnotou odvozenou od velkého množství obličejů. Na obrázku se potom označí struktura, která nejlépe odpovídá obličeji.

Dalším velkým problémem je různé natočení obličeje. Natrénovaná neuronová síť proto hledá na obličeji 68 bodů, podle kterých se potom obličej vyrovná tak, aby byly oči a ústa přibližně uprostřed.
Odkazy:
Vahid Kazemi and Josephine Sullivan: One Millisecond Face Alignment with an Ensemble of Regression Tree
Viola–Jones object detection framework
NavneetDalalandBillTriggs: HistogramsofOrientedGradientsforHumanDetection

Další neuronová síť na vyrovnaném obličeji změří 128 různých parametrů. Nikdo netuší, o jaké parametry jde. Podstatné je, že pro stejný obličej vycházejí tyto parametry velice blízko sebe.
Pro vyhledání obličeje v databázi se používá embedding. Těchto 128 charakteristik totiž představuje souřadnice v 128D prostoru, takže stačí do mapy (databáze) zabodnout magické stoosmadvaceti dimenzionální kružítko (algoritmus KNN) a co je uvnitř kružnice, to je naše hledaná osoba.
